1. 디스크 스케줄링의 개념
디스크는 가장 많이 사용하는 보조 메모리 중 하나로, 마치 레코드 판을 여러 개 중첩해서 놓은 것과 비슷하다. 레코드 판의 경우, 노래를 청취한다면 그 레코드의 순서대로 청취하게 될 것이다. 그러나 디스크는 헤드가 임의의 섹터를 랜덤하게 참조할 수 있고, 빠르게 데이터를 읽을 수 있으며, 메인 메모리보다 많은 양의 데이터를 저장할 수 있다.
1.1 디스크 스케줄링의 중요성
디스크 예약은 디스크에 도착하는 I/O 요청을 예약하기 위해 여러 운영체제에서 수행된다. 그래서 디스크 스케줄링을 사실상의 I/O 스케줄링이라고도 부르는 것이다. 여기서 I/O 요청은 서로 다른 프로세스에 의해 여러 개가 도착할 수 있으며, 디스크 컨트롤러는 한 번에 하나의 I/O 요청만 처리할 수 있다. 그렇게 되면, 밀린 요청은 대기열에서 기다려야 할 것이다. 입출력에 대한 처리를 하는 것이므로 디스크 스케줄링이 중요하다고 할 수 있는 것이다.
1.2 디스크 엑세스 시간

ㄱ. 탐색 시간(Seek Time)
탐색 시간은 데이터를 읽거나 현 위치에서 특정 트랙으로 디스크 헤드가 이동하는 데 소요되는 시간을 말한다. 일반적으로 최소 평균 탐색 시간을 제공하는 디스크 스케줄링 알고리즘이 좋다.
ㄴ. 회전 지연 시간(Rotation Delay Time, Rotational Latency)
가고자 하는 섹터가 디스크 헤드까지 도달하는 데 걸리는 시간을 말한다. 역시나 최소 회전 대기 시간을 제공할수록 더욱 좋은 알고리즘이라 할 수 있다.
ㄷ. 전송 시간(Transfer Time)
전송 시간은 데이터를 전송하는 데 걸리는 시간이다. 디스크의 회전 속도와 전송되는 바이트 수에 따라 다르다고 보면 된다.
* 디스크 엑세스 시간 = 탐색 시간 + 회전 지연 시간 + 전송 시간
2. 디스크 스케줄링의 종류
ㄱ. FCFS(First Come First Served)

FCFS는 모든 디스크 스케줄링 알고리즘 중 가장 간단한 것이다. FCFS에서는 요청이 디스크 대기열에 도착하는 순서대로 처리된다.
위 그림에서 현재 위치는 50이고, 요청 순서는 82, 170, 43, 140, 24, 16, 190이 된다.
따라서 디스크 암이 이동하는 총 거리는 642가 될 것이다.
FCFS의 장점은 모든 요청에 공정한 기회가 주어진다는 것이다. 빠르면 장땡이니 말이다. 또한, 그에 따라 무기한 연기는 없을 것이기도 하다. 반면, 단점으로는 공정할 뿐, 최적화와는 거리가 멀다는 것이다. 그렇기에 최상의 서비스를 제공하지 못할 가능성이 크다.
ㄴ. SSTF(Shortest Seek Time First)

SSTF에서는 탐색 시간이 가장 짧은 요청이 먼저 실행된다. 따라서 모든 요청의 검색 시간은 대기열에서 미리 계산된 다음, 계산된 검색 시간에 따라 예약되는 것이다. 결과적으로, 디스크 암 근처의 요청이 먼저 실행된다. SSTF는 평균 응답 시간을 줄이고, 시스템 처리량을 증가시키기 때문에 확실히 FCFS에 비해서는 개선된 것이라 말할 수 있을 것이다.
위 그림에서 현재 위치는 50이고, 요청 순서는 82, 170, 43, 140, 24, 16, 190이지만, 디스크 암이 이동하는 거리는 (50-43)+(43-24)+(24-16)+(82-16)+(140-82)+(170-140)+(190-170)= 208이 된다.
SSTF는 위에서도 말했듯, 평균 응답 시간이 줄어들고 처리량이 증가하는 강점을 지닌다. 그러나 탐색 시간을 미리 계산하기 위한 오버헤드가 발생하고, 들어오는 요청에 비해 탐색 시간이 더 긴 경우에 요청에 대한 기아 현상이 발생할 수 있을 것이다.
ㄷ. SCAN(엘레베이터 알고리즘)

SCAN 알고리즘에서 디스크 암은 특정 방향으로 이동하여 해당 경로로 들어오는 요청을 처리하고, 디스크 끝에 도달한다. 한쪽 방향으로 끝까지 밀고 나가는 것이 특징이다. 그런 다음, 방향을 바꾸어 해당 경로에 도착하는 요청을 다시 처리하게 된다. 이 모습이 마치 엘레베이터 같기 때문에 엘레베이터 알고리즘이라 불리는 것이다. 이 알고리즘에서 중간 범위에 있는 요청은 상대적으로 더 처리될 것이고, 양 극단에 있는 요청일 수록 더욱 많이 기다리게 될 것이다.
위 그림에서 현 위치 50에 요청 순서는 동일하지만, 이동거리는 (199-50)+(199-16)= 332가 된다.
SCAN 알고리즘의 장점은 높은 처리량, 응답 시간의 낮은 변동, 평균 응답 시간이 될 것이다. 반면, 단점은 명확하게 한가지가 있는데, 이미 지나친 곳에서의 요청은 매우 긴 대기 시간을 갖게 된다는 점이다.
ㄹ. C-SCAN(Circular SCAN)

기존의 SCAN 알고리즘에서는 디스크 암이 방향을 바꾸어 스캔된 경로를 다시 스캔하게 된다. 따라서 너무 많은 요청이 반대편 끝에서 대기할 수도 있고, 스캔한 영역에 대기 중인 요청이 거의 없을 수도 있다. 이러한 상황을 고려한 알고리즘이 C-SCAN 알고리즘이다. 이 알고리즘은 마치 디스크 암이 원형 방식으로 움직이는 것처럼 보인다. 항상 헤드는 안쪽에서 바깥쪽으로 이동한다. 위 그림을 통해 이해를 돕자면, 헤드는 항상 오른쪽으로 움직이며 처리한다. 오른쪽 끝에 도달하면, 왼쪽으로 크게 갔다가 다시 오른쪽으로 이동하며 요청을 처리하는 것이다.
따라서 위 그림의 경우, 이동거리는 (199-50)+(199-0)+(43-0)= 391이 된다.
C-SCAN은 SCAN에 비해 더욱 균일한 대기 시간을 제공하는 강점을 지닌다.
ㅁ. LOOK

LOOK 알고리즘은 SCAN과 유사하지만, 헤드는 굳이 끝까지 이동하지는 않는다. 대신, 헤드는 진행 방향에서 더 이상 요청이 없으면 방향을 바꾸는 것이다. LOOK은 SCAN의 개선된 알고리즘이라 볼 수 있다.
위 그림에서의 이동거리는 (190-50)+(190-16)= 314가 된다.
ㅂ. C-LOOK(Circular Look)
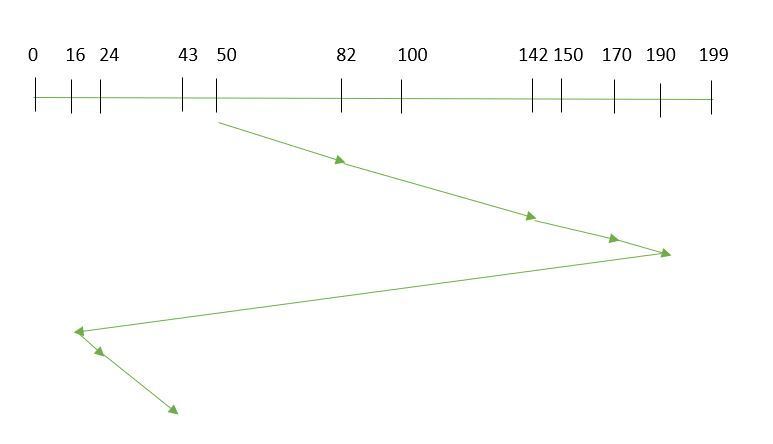
C-LOOK은 C-SCAN의 보완형이라 할 수 있다. C-SCAN와 매우 유사하지만, 헤드는 굳이 끝까지 이동하지는 않는다. 대신, 헤드는 진행 방향에서 더 이상 요청이 없으면 방향을 바꾸는 것이다. 디스크 끝까지 가는 불필요한 이동으로 인해 발생하는 추가 지연을 방지하는 알고리즘이라 볼 수 있다.
따라서 위 그림에서의 이동거리는 (190-50)+(190-16)+(43-16)= 341이 된다.
그밖에 기타 알고리즘으로는 다음과 같다.
RSS(Random Scheduling): 이는 스케줄링에 무작위 처리 시간, 무작위 기한, 무작위 가중치 등과 같은 무작위 속성이 포함되는 상황에서 사용된다. 그 상황에서는 이 알고리즘이 가장 적합하다고 볼 수 있다.
LIFO(Last In First Out): 후입 선출 알고리즘에서 최신 작업은 기존 작업보다 먼저 서비스될 것이다. 이를 통해 지역성 및 자원 활용도를 극대화할 수 있으나, 불공평성을 초래하며, 기아 현상이 발생할 가능성이 크다.
N-STEP: 여기서는 N개의 요청에 대해 버퍼가 생성된다. 버퍼에 속한 모든 요청은 한 번에 처리된다. 또한, 버퍼가 가득 차게 되면 새로운 요청은 이 버퍼가 아닌 다른 버퍼로 전송된다. 이렇게 N개의 요청이 처리되면, 또 다른 상위 N개의 요청을 처리할 것이다. 일종의 블록 처리라고도 볼 수 있을 것이다. 이 알고리즘을 통한다면 요청의 부족 현상을 완전히 제거할 수 있게 된다.
F-SCAN: 이 알고리즘은 2개의 하위 대기열을 사용한다. 검색하는 동안 첫 번째 대기열의 모든 요청이 처리되고, 새로 들어오는 요청이 두 번째 대기열에 추가된다. 첫 번째 대기열의 기존 요청이 처리될 때까지 새로운 요청은 모두 중단된 상태로 유지되는 알고리즘이다.
'보안 > 개념' 카테고리의 다른 글
| FAT, NTFS, EXT 총정리 (1) | 2023.12.27 |
|---|---|
| 유닉스 파일 시스템 구조 총정리 (2) | 2023.12.26 |
| 교착상태 총정리 (0) | 2023.12.25 |
| 임계 영역 총정리 (0) | 2023.12.24 |
| 스펨 메일 차단 총정리 (2) | 2023.12.23 |