[6주차] 클라우드의 컨테이너
학습목표
1. 컨테이너의 개념을 정의하고 그것의 용도를 식별하기
2. 쿠버네티스와 구글 쿠버네티스 엔진의 목적고 사용사례 파악하기
[6-1] 컨테이너 소개
이번 섹션에서는 컨테이너를 살펴보고, 컨테이너가 어떻게 사용되는지 이해하도록 한다.

IaaS를 이용하면, 하드웨어를 가상화하기 위해 가상 머신을 사용함으로써 컴퓨트 리소스를 다른 개발자들과 공유할 수 있다. 이를 통해 각 개발자는 그들의 OS를 배포하고, 하드웨어에 엑세스하며, RAM, 파일 시스템, 네트워킹 인터페이스 등에 엑세스할 수 있는 자체 포함 환경에서 그들의 애플리케이션을 구축할 수 있다. 여기가 바로 컨테이너가 들어오는 지점이다. 컨테이너의 아이디어는 패스 내 워크로드의 독립적인 확장성과 IaaS 내 OS와 하드웨어의 추상화 계층을 제공하는 것이다.

또한, 구성 가능한 시스템으로, 우리가 선호하는 런타임, 웹 서버, 데이터베이스나 미들웨어를 설치할 수 있을 것이다. 디스크 공간, 디스크 입출력, 또는 네트워킹과 같은 기본 시스템 리소스를 구성하고, 원하는 대로 빌드할 수도 있다. 하지만 유연성에는 비용이 수반된다. 컴퓨트의 가장 작은 단위는 VM이 있는 앱이다. 게스트 OS는 크기가 클 수도 있고, 심지어 GB 단위일 수도 있으며, 부팅하는 데 몇 분이 걸릴 수 있다. 애플리케이션에 대한 수요가 증가함에 따라, 전체 VM을 복사하고, 앱의 각 인스턴스에 대해 게스트 OS를 부팅해야 하므로 속도가 느리고, 비용은 증가할 수 있다. 컨테이너는 파일 시스템과 하드웨어의 자체 파티션에 대한 엑세스 권한이 제한된 코드와 그 종속성을 둘러싼 보이지 않는 상자다. 생성하는 데에 몇 가지 시스템 호출만 필요하며, 프로세스 만큼이나 빠르게 시작된다. 각 호스트에 필요한 것은 컨테이너를 지원하는 OS 커널과 컨테이너 런타임이다. 기본적으로, OS는 가상화되고 있다. 그것은 패스와 같은 스케일이지만, IaaS와 거의 같은 유연성을 제공한다. 따라서 코드가 휴대하기 매우 쉽고, OS와 하드웨어는 블랙 박스로 취급될 수 있다. 변경하거나 리빌딩하는 것 없이 개발에서 스테이징, 제작으로, 랩탑에서 클라우드로 전환할 수 있다.

예를 들어, 웹 서버를 확장한다고 가정하자. 컨테이너를 사용하면 이 작업을 몇 초만에 수행할 수 있으며, 단일 호스트의 워크로드의 크기에 따라 컨테이너를 수십 혹은 수백 개 배포할 수 있다. 이는 하나의 컨테이너를 확장하여 단일 호스트에서 전체 애플리케이션을 실행하는 간단한 예시에 불과하다.

그러나 마이크로서비스처럼 각각의 고유한 기능을 수행하는 많은 컨테이너를 사용하여 애플리케이션을 구축하길 원할 수도 있다. 이런 벙식으로 구축하고 네트워크 커넥션들로 연결하면, 그것들을 모듈식으로 만들고 쉽게 배포할 수 있으며, 호스트 그룹 간에 독립적으로 확장할 수 있다. 호스트는 앱에 대한 수요가 변경되거나 호스트가 실패함에 따라 확장 및 축소를 수행하고, 컨테이너를 시작 및 중지할 수 있다.
[6-2] 쿠버네티스

컨테이너화된 애플리케이션을 관리하고 확장하는 데 도움을 주는 제품이 바로 쿠버네티스다. 따라서 애플리케이션과 워크로드를 확장할 때 시간과 노력을 절약하기 위해 구글 쿠버네티스 엔진(GKE)을 사용하여 쿠버네티스가 부트스트랩될 수 있다. 그렇다면 쿠버네티스는 무엇일까? 쿠버네티스는 컨테이너화된 워크로드와 서비스를 관리하기 위한 오픈 소스 플랫폼이다. 그를 통해 많은 호스트에서 많은 컨테이너를 쉽게 조정하고, 마이크로서비스로 쉽게 확장하며, 쉽게 배포, 롤아웃 및 롤백이 가능하다.

가장 높은 레벨에서, 쿠버네티스는 클러스터라고 불리는 노드 집합에 컨테이너를 배포하는 데 사용할 수 있는 API 집합이다. 그 시스템은 제어 평면(control plane)으로 실행되는 기본 구성요소 집합과 컨테이너를 실행하는 노드 집합으로 나뉜다. 쿠버네티스에서 노드는 기계와 같은 컴퓨팅 인스턴스를 나타낸다. 알아두어야 할 게, 이는 컴퓨터 엔진에서 실행되는 가상 머신인 구글 클라우드에서의 노드와는 다르다는 것이다. 우리는 애플리케이션 세트와 어떻게 그것들이 서로 상호작용하는지 설명할 수 있으며, 쿠버네티스는 이를 구현하는 방법을 결정한다. 하나 이상의 컨테이너 주변에 래퍼를 사용함으로써 노드에 컨테이너를 배포하는 것이 파드(Pod)를 정의한다. 파드는 쿠버네티스에서 생성하거나 배포할 수 있는 가장 작은 단위다. 이는 애플리케이션의 구성요소 또는 전체 앱으로 클러스터에서 실행 중인 프로세스를 나타낸다. 일반적으로, 파드당 컨테이너가 하나만 있지만, 의존성이 강한 여러 개의 컨테이너가 있는 경우, 이를 패키징하여 단일 파드에 넣고, 이들 간에 네트워킹과 스토리지 리소스를 공유할 수 있다. 파드는 컨테이너를 위한 고유한 네트워크 IP와 포트 세트, 그리고 어떻게 컨테이너가 실행돼야 하는지 제어하는 구성 가능한 옵션을 제공한다. 쿠버네티스에 있는 파드에서 컨테이너를 실행하는 한 가지 방법은 kubectl run 커맨드를 사용하는 것이다. 이 명령은 파드 내부에서 실행되는 컨테이너로 배포를 시작한다. 배포는 동일한 파드의 복제 그룹을 나타내며, 심지어 실행 중인 노드에 장애가 발생할 경우에도 파드를 계속 실행한다. 배포는 애플리케이션 또는 심지어 전체 앱의 구성 요소를 나타낼 수도 있다. 프로젝트에서 실행 중인 파드 목록을 보려면, kubectl get pods 명령을 실행하면 된다. 쿠버네티스는 파드에 고정 IP 주소를 사용해서 서비스를 생성한다. 그리고 한 컨트롤러는 클러스터 외부의 다른 사용자가 엑세스할 수 있도록 공용 IP 주소를 가진 외부 로드 밸런서를 해당 서비스에 연결해야 한다고 말한다. GKE에서, 그 로드 밸런서는 네트워크 로드 밸런서로 생성된다. 해당 IP 주소에 도달하는 모든 클라이언트는 서비스 뒤에 있는 파드로 라우팅될 것이다. 서비스는 논리적인 파드 집합과 그것들에 엑세스하기 위한 정책을 정의하기 위한 추상이다. 배포를 통해 파드를 생성하거나 파괴하면, 파드에는 자체 IP 주소가 할당되겠지만, 그런 주소는 시간이 지나면 안정적으로 유지되지는 않는다. 서비스 그룹은 파드의 집합이며, 이들을 위해 안정적인 엔드포인트 또는 고정된 IP 주소를 제공한다.
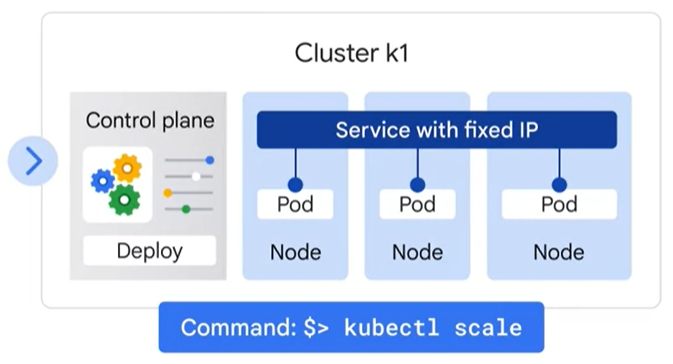
예를 들어, 만약 프론트엔드와 백엔드라 불리는 두 세트의 파드를 만들고 그것들을 그들의 서비스 뒤에 두게 되면, 백엔드 파드는 바뀌겠지만, 프론트엔드는 이를 인식하지 못한다. 그들은 단순히 백엔드 서비스를 말한다. 배포를 확장하기 위해서는 kubectl scale 커맨드를 실행해야 한다.

이 예시에서, 배포 환경에 3개의 파드가 생성되고, 그것들은 서비스 뒤에 배치되며, 하나의 고정 IP 주소를 공유한다. 다른 종류의 매개변수로 자동 스케일링을 사용할 수도 있다. 예를 들어, CPU 사용률이 특정 한계에 도달하게 되면, 파드 수가 증가하도록 지정할 수 있다. 지금까지, 우리는 노출과 확장과 같은 명령어들을 실행하는 방법에 대해 살펴 보았다. 이 작업들은 쿠버네티스를 단계적으로 테스트하고 배우는 데 있어 효과적이다. 하지만 쿠버네티스의 진정한 힘은 선언적인 방식으로 수행할 때 나온다. 명령어를 발행하는 대신, 원하는 상태가 무엇인지를 쿠버네티스에게 알려주는 구성 파일을 제공하고, 쿠버네티스가 이를 수행하는 방법을 결정하는 것이다. 우리는 배포 구성 파일을 통해 이를 수행한다. kubectl get 배포나 kubectl describe 배포를 사용함으로써, 배포를 체크해 적절한 수의 사본이 실행되고 있는지 확인할 수 있다.

3개가 아닌 5개의 사본을 실행하려면, 배포 구성 파일을 업데이트하고, kubectl apply 명령을 실행하여 업데이트된 구성 파일을 사용하면 된다. kubectl get 서비스를 사용함으로써 서비스의 외부 IP를 가져오고, 클라이언트로부터 공용 IP 주소에 도달하면, 이전과 같이 엔드포인트에 도달할 수 있다. 마지막으로, 앱의 새로운 버전으로 업데이트하고 싶을 땐 어떻게 해야 할까? 사용자들 앞에서 새로운 코드를 얻기 위해 컨테이너를 업데이트하고 싶겠지만, 한 번에 모든 변경사항을 출시하는 것은 위험하다.

따라서 이런 경우, kubectl rollout을 사용하거나, 배포 구성 파일을 변경한 다음 kubectl apply를 사용하여 변경 사항을 적용한다. 그러면 새로운 파드들은 새로운 업데이트 전략에 따라 생성될 것이다. 다음은 새 버전의 파드를 개별적으로 만들고, 이전 파드 중 하나를 파괴하기 이전에 새 파드를 사용할 수 있을 때까지 기다리는 예제 구성이다.
[6-3] 구글 쿠버네티스 엔진

이제 컨테이너와 쿠버네티스에 대한 기본적인 이해를 마쳤으니, 구글 쿠버네티스 엔진(GKE)을 다루도록 한다. GKE는 구글이 클라우드에서 호스트하는 관리형 쿠버네티스 서비스다. GKE 환경은 여러 머신, 구체적으로 컴퓨트 엔진 인스턴스들을 그룹화하여 클러스터를 형성하는 것으로 구성된다. 구글 클라우드 콘솔 또는 Cloud Software Development Kit에서 제공하는 gcloud 명령을 사용하여 쿠버네티스 엔진으로 쿠버네티스 클러스터를 생성할 수 있다. GKE 클러스터는 사용자 정의될 수 있으며, 그것들은 다른 머신 유형, 노드 수 및 네트워크 세팅을 지원한다. 쿠버네티스는 클러스터와 상호작용하는 메커니즘을 제공한다. 쿠버네티스 명령과 리소스는 애플리케이션을 배포 및 관리하고, 관리자 작업을 수행하며, 정책을 설정하고, 배포된 워크로드의 상태를 모니터링하는 데 사용된다. GKE 클러스터를 실행하면, 구글 클라우드가 제공하는 고급 클러스터 관리 기능의 이점이 따라온다. 여기에는 컴퓨트 엔진 인스턴스에 대한 구글 클라우드의 로드 밸런싱, 추가적인 유연성을 위한 클러스터 내의 노드의 하위 집합을 지정하는 노드 풀, 클러스터의 노드 인스턴스 수 자동 확장, 클러스터의 노드 소프트웨어를 위한 자동 업그레이드, 노드 상태 및 가용성을 유지하기 위한 노드 자동 복구, 클러스터의 가시성을 위해 구글 클라우드 운영 제품군을 사용한 로깅 및 모니터링이 포함된다.

쿠버네티스를 시작하려면 GKE의 클러스터에 있어야 하며, gcloud container clusters create k1 명령을 실행하기만 하면 된다.
6주차에는 섹션도 적고, 실습도 딱히 없다. 이것으로 6주차를 마치도록 한다.