1. 데이터 타입의 개념
모든 변수는 선언 중에 데이터 타입을 사용하여 저장할 데이터 유형을 제한한다. 따라서 데이터 타입은 변수에 저장할 수 있는 데이터 유형을 알려주는 데 사용된다고 할 수 있다. C++에서 변수가 정의될 때마다 컴파일러는 해당 변수에 대해 선언된 데이터 유형에 따라 메모리를 할당한다. 그런데 여기서 모든 데이터 유형에는 서로 다른 양의 메모리가 필요하다는 것을 알아야 한다.
C++는 매우 다양한 데이터 유형을 지원하며, 그렇기에 우리는 애플리케이션의 필요에 맞는 데이터 유형을 선택할 수 있다. 데이터 유형은 저장할 값의 크기와 유형을 지정한다. 그러나 C++ 명령어는 모든 기계에서 동일하지만 각 데이터 유형을 조작하기 위한 저장 표현과 기계 명령어는 기계마다 다르기 때문에 이에 유의할 필요가 있다.

한편, C++는 다음과 같은 데이터 유형을 지원한다. 그 안의 세부 가지는 위의 그림과 같다.
① Primary or Built-in or Fundamental data type
② Derived data types
③ User-defined data types
2. 세 가지의 주요 데이터 타입
① 기본 데이터형(Primitive Data Types)
이러한 데이터 유형은 기본 제공 데이터 또는 미리 정의된 데이터 유형으로 사용자가 직접 변수를 선언하는 데 사용할 수 있다. int, char, float, bool 등 말이다. C++에서 사용할 수 있는 원시 데이터 유형은 다음과 같다.
Integer / Character / Boolean / Floating Point / Double Floating Point /Valueless or Void / Wide Character
⑴ 정수(Integer): 정수 데이터 유형에 사용되는 키워드는 int다. 정수는 일반적으로 4바이트의 메모리 공간이 필요하며, -2147483648에서 2147483647 사이의 범위를 갖는다.
⑵ 문자(Character): 문자 데이터 유형은 문자를 저장하는 데 사용된다. 문자 데이터 유형에 사용되는 키워드는 char이다. 문자는 일반적으로 1바이트의 메모리 공간이 필요하며, -128에서 127 또는 0에서 255 사이의 범위를 갖는다.
⑶ 불(Boolean): 불 데이터 유형은 불 또는 논리 값을 저장하는 데 사용된다. 불 변수는 true 또는 false를 저장할 수 있다. 부울 데이터 유형에 사용되는 키워드는 bool이다.
⑷ 부동 소수점(Floating Point): 부동 소수점 데이터 유형은 단정밀 부동 소수점 값 또는 소수점 값을 저장하는 데 사용된다. 부동 소수점 데이터 유형에 사용되는 키워드는 float이다. 부동 소수점 변수에는 일반적으로 4바이트의 메모리 공간이 필요하다.
⑸ 이중 부동소수점(Double Floating Point): 이중 부동소수점 데이터 유형은 고정밀 부동소수점 값이나 소수점 값을 저장하는 데 사용된다. 이중 부동소수점 데이터 유형에 사용되는 키워드는 double이다. 이것은 일반적으로 8바이트의 메모리 공간을 필요로 한다.
⑹ 무형(無): void는 값이 없음을 의미한다. 즉, void data type은 값이 없는 개체를 나타내는 것이다. void data type은 값을 반환하지 않는 함수에 사용된다.
⑺ 와이드 문자(Wide Character): 와이드 문자 데이터 형식도 문자 데이터 형식이지만, 이 데이터 형식은 일반 8비트 데이터 형식보다 크기가 크다. 그렇기에 wide인 것이다. 이것은 wchar_t로 표시되며ㅡ 일반적으로 2바이트 또는 4바이트의 길이를 갖는다.
⑻ sizeof () operator : sizeof () operator는 컴퓨터 메모리에서 변수/데이터 유형이 차지하는 바이트 수를 찾는 데 사용된다.
② 파생 데이터형(Derived Data Types)
원시 데이터 유형 또는 내장 데이터 유형에서 파생된 파생 데이터 유형을 말 그대로 파생 데이터 유형이라고 하며, 다음과 같은 네 가지 유형이 있다.
Function /Array / Pointer / Reference
⑴ 함수(Function): 함수는 잘 정의된 특정 작업을 수행하기 위해 정의된 코드 또는 프로그램 세그먼트의 블록이다. 함수는 일반적으로 사용자가 동일한 입력에 대해 동일한 코드 행을 계속해서 쓰지 않도록 정의된다. 모든 코드 행은 하나의 함수 안에 함께 들어 있으며, 필요한 곳이면 어디든지 호출할 수 있다. main()은 C++의 모든 프로그램에 정의된 기본 함수이다.
⑵ 배열(Array): 배열은 연속적인 메모리 위치에 저장된 항목의 집합이다. 배열의 아이디어는 많은 인스턴스를 하나의 변수에 표현하는 것이다.
⑶ 포인터(Pointer): 포인터는 주소를 상징적으로 표현하는 것이다. 이를 통해 프로그램은 참조에 의한 호출을 시뮬레이션할 수 있을 뿐만 아니라 동적 데이터 구조를 생성하고 조작할 수 있다.
⑷ 참조(Reference): 변수가 참조로 선언되면, 기존 변수의 대체 이름이 된다. 선언문에 &를 넣어 변수를 참조로 선언할 수 있다.
③ 추상 혹은 사용자 정의 데이터형(Abstract or User-Defined Data Types)
추상 혹은 사용자 정의 데이터형은 이름에서도 알 수 있듯, 사용자가 직접 정의한다. 예를 들어, C++ 또는 구조에서 클래스를 정의하는 것이다. C++는 다음과 같은 사용자 정의 데이터 유형을 제공한다.
Class / Structure / Union / Enumeration /Typedef defined Datatype
⑴ 클래스(Class): 클래스는 개체 지향 프로그래밍을 클래스로 이끄는 C++의 구성 요소이다. 사용자 정의 데이터 유형으로 자체 데이터 구성원과 구성원 기능을 보유하며, 해당 클래스의 인스턴스를 만들어 액세스하고 사용할 수 있다. 클래스는 개체에 대한 청사진과 같다고 말할 수 있다.
⑵ 구조(Structure): 구조는 C++의 사용자 정의 데이터 유형이다. 구조는 다른 유형의 항목을 단일 유형으로 그룹화하는 데 사용할 수 있는 데이터 유형을 만든다.
⑶ 공용체(Union): 구조와 마찬가지로, 공용체도 사용자 정의 데이터 유형이다. 공용체에서는 모든 구성원이 동일한 메모리 위치를 공유한다.
⑷ 열거형(Enumeration): 열거형도 역시나 사용자 정의 데이터 유형이다. 주로 정수형 상수에 이름을 할당하는 데 사용되며, 이름을 사용하면 프로그램을 쉽게 읽고 유지 관리할 수 있다.
⑸ Typedef: C++에서는 typedef 키워드를 사용하여 명시적으로 새로운 데이터 유형 이름을 정의할 수 있다. typedef를 사용하면 기존 유형의 이름을 정의하는 것이 아니라 새로운 데이터 클래스가 생성된다. 이렇게 하면 typedef 문만 변경하면 되므로 프로그램의 휴대성이 향상된다고도 볼 수 있을 것이다. typedef를 사용하면 표준 데이터 유형에 대한 설명적 이름을 허용하여 코드를 자체 문서화하는 데 도움이 될 수도 있다.
3. 데이터 타입 수정자
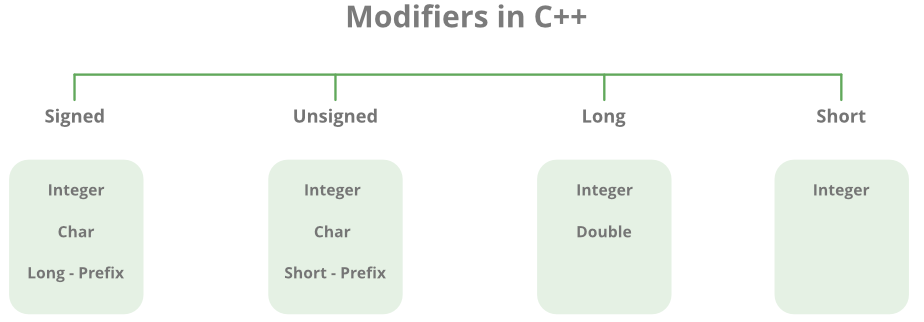
이름에서 알 수 있듯이 데이터 타입 수정자는 내장된 데이터 유형과 함께 사용되어 특정 데이터 유형이 보유할 수 있는 데이터 길이를 수정한다.
하나하나 길이를 따져보면,
signed char: 1bytes *단위 이하동일
unsigned char: 1
short int: 2
unsigned short int: 2
wchar_t: 2 or 4
unsigned int: 4
int: 4
long int: 4
unsigned long int: 4
float: 4
long long int: 8
unsigned long long int: 8
double: 8
long double: 12
4. 데이터 타입의 장단점
①장점
- 데이터 유형은 프로그램에서 데이터를 분류하고 정리할 수 있는 방법을 제공하여 이해하고 관리하기 쉽다.
- 각 데이터 유형에는 저장할 수 있는 특정 범위의 값이 있으므로 저장 중인 데이터 유형을 보다 정확하게 제어할 수 있다.
- 데이터 유형은 데이터를 사용하고 조작하는 방법에 대한 엄격한 규칙을 적용하여 프로그램의 오류와 버그를 방지하는 데 도움이 될 것이다.
- C++에서는 다양한 데이터 유형을 제공하여 우리가 특정 작업에 가장 적합한 유형을 선택할 수 있다.
② 단점
- 잘못된 데이터 유형을 사용하면 프로그램에서 예기치 않은 동작과 오류가 발생할 수 있다.
- long double이나 char arrays와 같은 일부 데이터 유형은 메모리를 많이 차지할 수 있으며, 과도하게 사용할 경우 성능에 영향을 미칠 수 있다.
- C++의 복합형 시스템은 초보자 입장에서는 언어를 효과적으로 배우고 사용하는 것을 어렵게 할 수 있다.
- 데이터 유형을 사용하면 프로그램에 추가적인 복잡성을 추가하여 읽고 이해하기가 더 어려워질 수도 있다.
'C++' 카테고리의 다른 글
| C++ if else문 총정리 (0) | 2024.03.08 |
|---|---|
| C++ if문 총정리 (0) | 2024.03.08 |
| C++ 리터럴(Literals) 총정리 (0) | 2024.02.20 |
| C++ 정적 키워드 총정리 (0) | 2024.02.20 |
| C++ 변수(Variables)의 범위- 지역, 전역 총정리 (0) | 2024.02.17 |